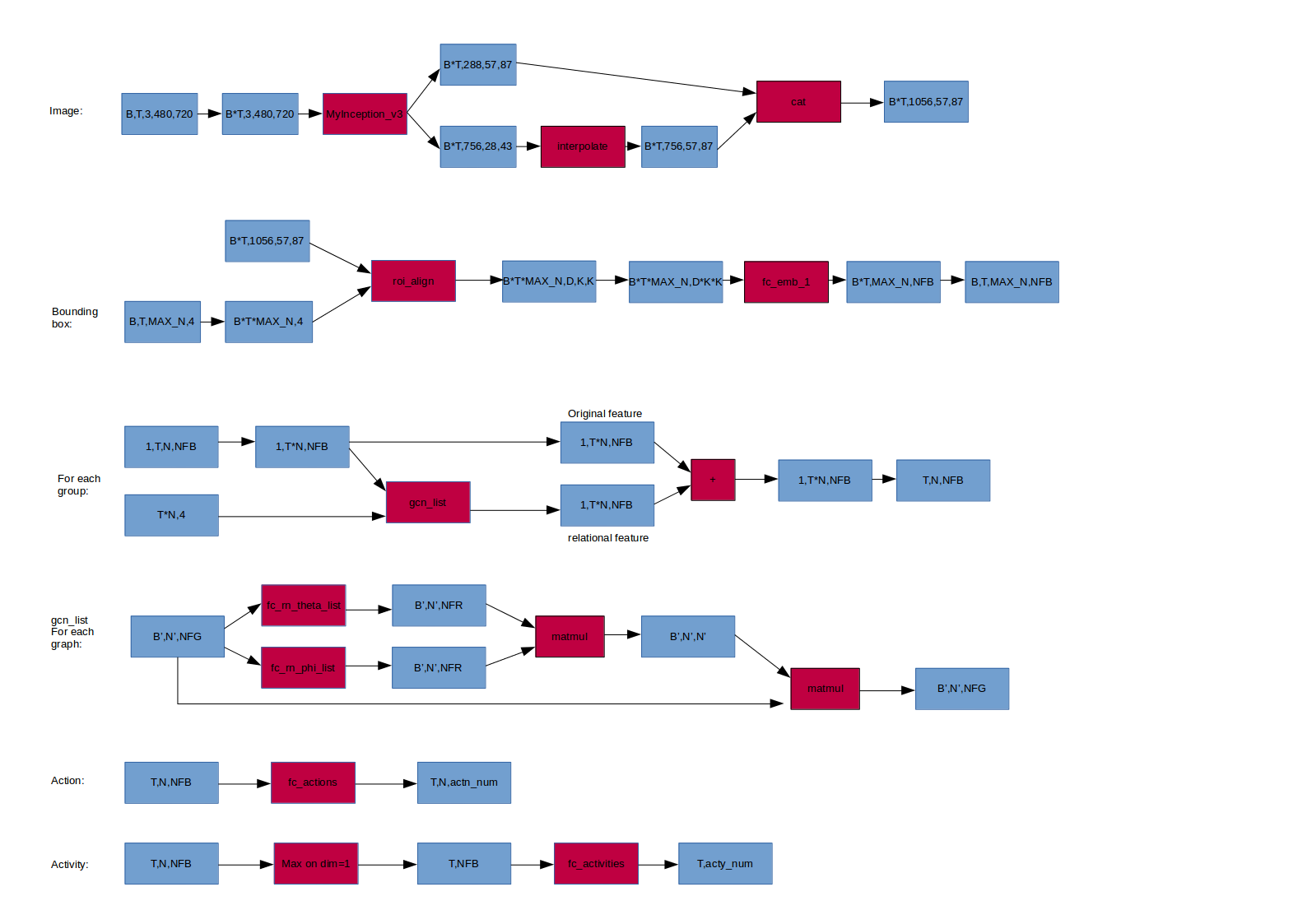
In the collective dataset, every 10 frames are labelled a group action, the 10 frames has collection among each other. We call each 10 frame as a group. We take T frames from the 10 frames to train the group action. Each batch we deal with B groups, each group we take T frames. Therefore, the input dimension is (B, T , 3, 480, 720). Assuming in each frame the number of bounding box is N, we then have T*N bounding boxes in each group. There are two categories of the feature vectors: original feature and relational feature. Origian feature captures actor action feature from the their bounding box and the image, while relational feature captures actor relation feature from the orignal feature and the position of their bounding boxes. Finally, original feature and relational feature are aggregated and fed into classifiers of group activity and individual action.
Abstract
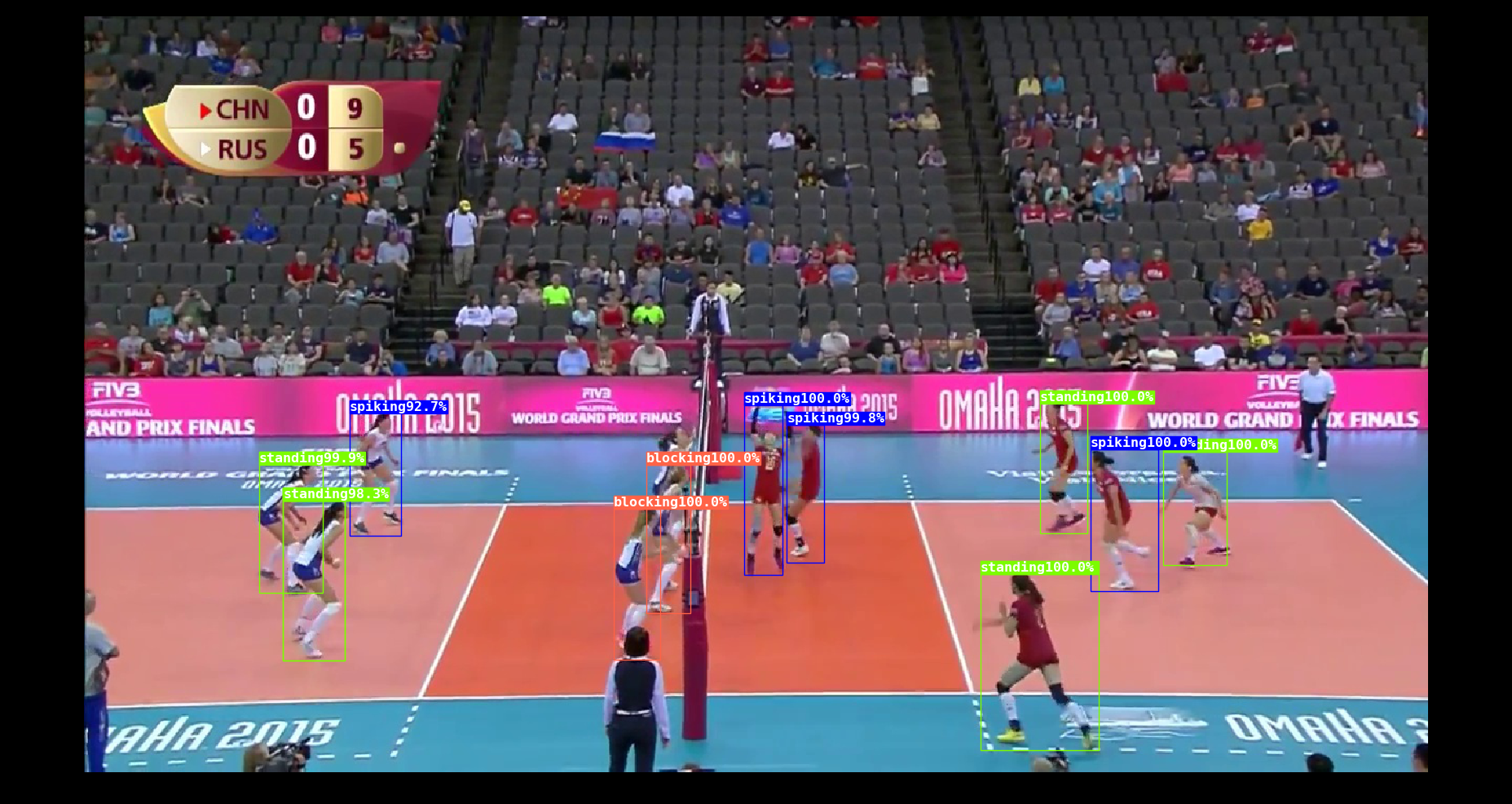
This is an implementation of CVPR 2019 paper "Learning Actor Relation Graphs for Group Activity Recognition". Our code is based on their accompanying code. Original feature and relational feature are extracted for each actor. There two features are combined to finish the classification job. We append a LogSoftmax to the last layer to normalize the resutls into a probability distribution, which is shown above the bounding boxes in the video.